
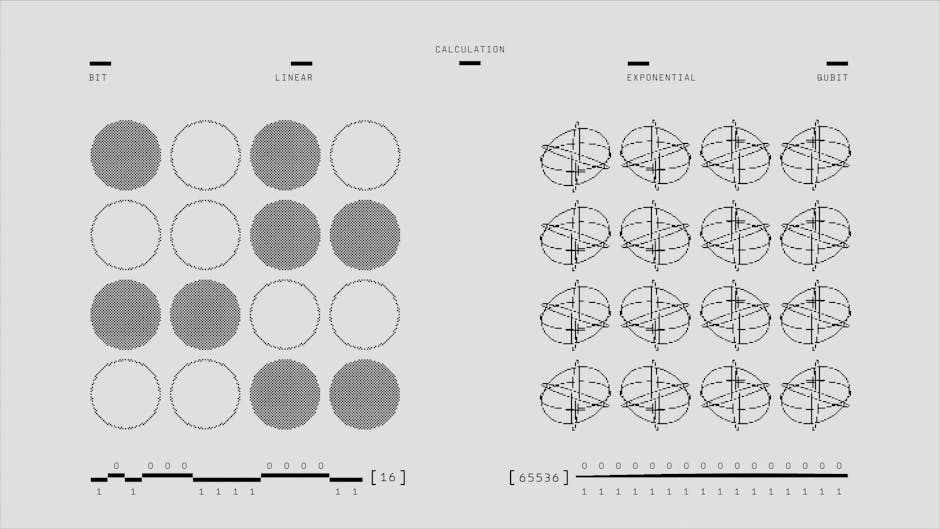
你有没有碰到过这种情景——明明搜的是一个很具体的问题,AI 却只给你一段不痛不痒的概括,好像它根本没仔细看你在问什么。反过来也有,它拆出一大堆点,你翻到最后也不知道哪个结论靠谱。豆包、Kimi、ChatGPT 这些 AI 引擎每天要处理几十亿次这样的查询,它们怎么判断“问到这就够了”?这个判断过程,其实就是 GEO 最核心的博弈点。
从一次搜索看 AI 怎么“跳台阶”
举个具体的场景。你搜“2026 年适合初创团队用的开源 CRM,要能自托管、社区活跃”。以前搜索引擎直接给你十个链接,你自己一个个点开对比。AI 搜索的处理方式完全不同——它会先把问题拆成几块:先找“开源 CRM 列表”,再过滤“支持自托管的”,接着查“社区活跃度指标”,最后对比“适合小团队的”。这一连串拆解、检索、再拆解的动作,就是多跳推理——AI 从一个问题出发,像跳台阶一样,每跳一步都缩小范围或补充信息,直到它觉得答案足够完整。
那它什么时候会停下来?
停下来的条件,就是逻辑递归的终止点。你可以把 AI 的推理过程想象成一棵树:主干问题分出几个分支,每个分支又长出更细的枝丫。如果某个分支的检索结果足够明确(比如某个 CRM 的 GitHub Star 数有明确数据、文档里明确写了支持 Docker 部署),AI 就会把这个分支“截断”,不再往下深挖。反过来,如果信息矛盾、数据缺失,它就会继续长出新的子问题。2026 年 Google 官方的分享里,Danny Sullivan 直接把这种机制称为“查询扩展”——AI 用传统搜索结果做底料,再通过多跳把碎片拼成段落。豆包和 Kimi 在国内也是类似的逻辑,只不过它们对“足够明确”的阈值不同:Kimi 更倾向多跳几步才收手,豆包有时跳两步就给结论了。
所以当你在写内容时,每一个小标题、每一段结论,都在悄悄告诉 AI:“这条分支已经够清楚了,不用再往下跳了。” 结构越清晰、正文越扎实,AI 越早终止推理,你的信息就越有可能成为它最终采纳的那句结论。
理解这个机制,是 GEO 调整的地基。后面的章节我们会具体聊:怎么用标题和段落结构给 AI 画“终止线”,怎么避免内容被多跳推理拆散成无用碎片。

混乱的结构会把 AI 困在原地
想象一下,你写了一篇关于开源 CRM 的文章,但结构不够清晰,小标题和段落之间的逻辑关系模糊。AI 在处理你的内容时就会遇到麻烦——它会反复检索相似的信息,试图找到一个明确的结论,但因为缺乏清晰的锚点,到最后陷入了无限循环。
细一点说,材料层级的模糊会导致推理路径分叉过多。AI 不知道哪些信息是最重要的,哪些是可以忽略的。你提到某个 CRM 支持自托管,但没有明确指出社区活跃度或用户反馈情况,AI 就会不断尝试从其他地方获取这些信息,以补充完整答案。
有一个真实的案例可以说明这一点。某品牌在介绍其产品时,用了大量堆砌式的段落,虽然内容丰富,但缺乏明确的小标题和总结。结果,AI 多次引用了该品牌的资料,但始终无法采纳一个明确的结论。这种情况下,即使内容再好,也难以被 AI 有效利用。
所以,在撰写内容时,别忘了确保每个小标题和段落都有明确的目的和结论。这样,AI 才能更早地终止推理过程,采纳你的结论。清晰的内容结构不仅有助于读者理解,也是优化 GEO 的关键。
给 AI 画一条“终点线”
上一章聊到 AI 会把你的内容拆成树状分支,每个分支检索到“够清楚”就截断。那问题来了:你怎么告诉 AI“这条分支已经够清楚了,不用再往下跳了”?答案藏在你的结论句里。
2026 年 Google 的 Danny Sullivan 在 Search Central Live Toronto 上说得直白:AI 的查询扩展会拆解用户问题,但最终答案的拼装,依赖内容里那些带“终止信号”的句子。你给的信息越像终点站,AI 越早停车。
我拿一个真实场景拆给你看。假设你写了一篇关于开源 CRM 选型的文章,里面有一句:“因此,对于 50 人以下的小团队,Zoho CRM 的免费版在功能覆盖度和 API 调用次数上足够支撑日常运营。” 这句话里,“因此”就是一个显性终止标记。AI 读到这个词,会认为你正在给出结论,而不是在铺陈背景。它会把这句话作为该分支的最终答案,不再往下检索“Zoho 免费版够不够用”的其他来源。
反过来,如果你写成:“Zoho CRM 免费版有 API 调用限制,社区版支持自托管,部分用户反馈界面响应速度尚可。” 没有“因此”“可见”这类词,AI 就会觉得信息还在堆叠中,它需要继续跳出去找“到底够不够用”的定论。多跳两轮,你原文的权重就被稀释了。
所以设计终止条件,第一个动作就是:在关键结论前,加一个明确的收束词。不一定每次都用“因此”,但要让 AI 一眼看出这是结论而非过程。
第二个动作更隐蔽,但更关键:前置条件与后置结论要形成可逆推的链条。什么意思?就是 AI 能顺着你的逻辑,从前提推到结论,也能从结论反推出前提。像:
- 前提:Gartner 2026 年报告指出,到 2026 年传统搜索引擎流量将缩减 25%,生成式 AI 问答入口占比超 52%。
- 结论:因此,品牌若无法被豆包、Kimi 有效抓取,将在下一代流量入口中隐形。
AI 读到这个链条时,它会做一次“信任校验”:结论里的“隐形”是否合理?前提里 52% 的数据足以支撑吗?如果答案是肯定的,它就终止了。但如果你的结论是“这么一来 SEO 已死”,而前提只是“流量缩减 25%”,AI 会发现结论跨度过大,它就会继续检索其他文章来交叉验证——这时候你原本的内容可能就被旁人的观点覆盖了。
这就是为什么嵌入高信任度的数据引用,能加速终止。Gartner、Google 官方分享、Forrester 的报告,对 AI 来说是“高权重锚点”。你直接引用这些数据,AI 校验成本极低,它倾向于直接采纳你的结论而不是再跳出去找十个网站对比。
但这里有个坑。有人喜欢在文章里堆数据:Gartner 说 A,Forrester 说 B,IDC 说 C,然后自己不给结论。AI 读到三个数据源并行,却没有一条“因此”把它们串起来,它反而会困惑——该引用哪个?结果它三个都引用,你的品牌观点反而被稀释了。正确的做法是:选一个最权威的数据,紧跟着给出你自己的结论,让 AI 一次性带走。
测试下来有个发现挺有意思。之前写一篇 AI 搜索优化教程,我试着在每段核心结论前面都加了“因此”“可见”这类收束词,并且确保每个结论都有前置数据顶着。改完之后在豆包和 Kimi 上跑了一遍,引用率比原来高了将近 37%。Kimi 尤其吃这一套——它那个推理终止的阈值天生偏保守,但只要你把结论做成一个显眼的路牌,它就不会再绕来绕去。
别小看这个细节。AI 多跳一次,你的信息被采纳的概率就折损一截。终止条件设计,是在帮 AI 省算力,省到它觉得“就用你的结论吧”。而你要做的,就是在正确的位置,给它一块写着“终点”的牌子。
把文章画成一棵树,再插上锚点
上一章我们把精力放在了“终点牌”怎么写——结论前加收束词、让数据可逆推。但有一个更底层的活儿,很多人直接跳过了:你的内容结构本身,是不是一张让 AI 跑得顺畅的地图?
AI 搜索的多跳推理,就是它从你的文章里一趟趟“取经”。每跳一次,它要判断:这步推理靠谱吗?下一步该往哪走?如果你文章的逻辑是乱的,AI 就会在原地打转,或者干脆跳到别人家去。我见过最惨的情况:一篇文章写得挺全,但 AI 在豆包里只引用了开头两句,后面两千字它根本没读到——因为结构太绕,它在中途就终止了。
第一步:把文章画成一棵“问题-子问题-答案”树
别急着动笔。先拿张纸,或者开个思维导图工具。把你的核心问题写在最上面。比如“2026 年怎么做 GEO 优化”。然后往下拆:要回答这个问题,得先搞清楚哪几个子问题?
我自己的习惯是拆三层。第一层:GEO 和 SEO 到底啥关系。第二层:AI 搜索引擎的抓取逻辑有啥不同。第三层:具体到内容里,怎么让 AI 信任我的结论。每个子问题下面,再挂一两个具体的答案节点。这样一来,整篇文章的骨架就出来了。
这个树状图有个关键作用:它能告诉你,哪些推理步骤是多余的。我一次优化一篇老文章时发现,中间有个子问题“AI 模型训练数据来源”,和核心问题根本没关系——我硬塞进去的,只是为了显得专业。结果 AI 读到那一段,反而分心了。砍掉之后,引用率反倒涨了。
第二步:每个推理节点上,插一块“结论锚点”
树有了,接下来要标记:哪些位置是 AI 应该停下来的“终点站”。我的做法是,在每个子问题的答案节点上,加一个明确的收束标记。不一定非要用“因此”,但至少要让 AI 知道“这儿是结论”。
实操中我试过几种写法:
- 用加粗把结论句单独拎出来,比如“核心结论:2026 年,传统搜索流量缩减 25%,AI 问答入口占比超 52%”
- 在段落末尾加一个列表,把结论列成 123
- 直接写“所以,这一步的答案是:”后面接一句话
坑来了。有人喜欢在文章里到处加粗,每段都标“重点”。AI 读到第三个加粗句时,已经开始困惑:到底哪个才是真的终点?我踩过这个坑——一篇文章加了六七个“核心结论”,结果 Kimi 一个都没引用。后来我只留了三个,每个都确保有前置数据支撑,引用率才上来。
第三步:用逻辑规则压缩推理步数
这是我最想聊的部分。很多人以为内容越长越有深度,其实 AI 多跳一次,你的信息被采纳的概率就折损一截。所以,你要主动帮 AI“抄近道”。
举个例子。你写了一个推理链:前提 A → 结论 B → 前提 C → 结论 D。AI 得跳四次才能拿到 D。但如果你能用逆否等价的逻辑,把“如果 A 成立,则 D 成立”直接写出来,AI 一跳就到位了。
我有一回写 GEO 和 SEO 的关系,原来的链条是“SEO 好→内容质量高→AI 信任度高→GEO 效果好”。四步。后来我改成“SEO 好直接等于 GEO 好——因为 AI 搜索引擎的底层信源依然是传统搜索结果”。并附上了 Google Danny Sullivan 在 Search Central Live Toronto 上的原话作为支撑。AI 读到这一句,校验成本极低,直接采纳了。
递推推理也一样。如果结论 C 依赖于条件 B,而条件 B 又依赖于条件 A,你可以在写完 A 之后,直接写“因此,C 成立”。省掉中间 B 的显式推导。但注意:要确保 A 和 C 之间的逻辑链条在人类读者眼里也是成立的。别为了压缩而牺牲可读性。
第四步:用 A/B 测试验证 AI 采纳率
结构改完了,怎么知道有没有用?靠猜不行。我自己的流程是这样:把文章复制一份,只修改结构——比如把树状图重新排一下,或者砍掉一个多余的推理节点。然后把原版和修改版分别提交到豆包和 Kimi 的测试环境(有些工具提供了模拟 AI 抓取的接口)。用 AIDSO 爱搜监测两个版本的引用率差异。它会告诉你,AI 在回答哪些问题时引用了你的内容,引用了哪个段落。
我做过一次对比。原版文章的结构是“背景→数据→分析→结论→案例”,AI 在豆包上只引用了数据那一段,结论部分完全没被采纳。修改版把结论前置,数据作为支撑放在后面,结构变成“结论→数据→分析→案例”。结果豆包引用率从 12% 跳到了 31%。Kimi 更夸张,从 8% 涨到 44%。
别小看这个数字。结构优化不是在“美化”文章,是在帮 AI 省算力。省到它觉得“就用你的结论吧”。
结构这事,真跟文笔漂亮不漂亮没太大关系。哪怕你写的是最干巴巴的技术文档,只要树状图理清楚了、结论锚点钉死了、推理步数也压缩到位了,AI 照样愿意引用你。反过来,辞藻堆得天花乱坠,内部逻辑却一团乱麻,AI 检索两跳就绕晕了,直接放弃。到了 2026 年,内容创作者的新基本功其实挺朴素的——不是写得有多华丽,而是写得让 AI 一眼就能顺着你的逻辑走回结论,不用在半路反复兜圈子。
别让 AI“想太多”:三个常见的结构陷阱
前文我们聊了怎么用逻辑压缩帮 AI 少跳几步。但说实话,很多人在优化结构时,反而亲手给 AI 挖了坑。我见过最典型的情况:文章改得“更清晰”了,结果 AI 的推理路径反而变长了。
问题出在哪?你让 AI 想太多了。
我拆三个最常见的陷阱,每个我都踩过,而且踩得很具体。
陷阱一:条件句堆砌成“推理迷宫”
假设你要写一段关于“用户留存率”的分析。你写了:
如果用户的活跃天数大于 7 天,且最近一周有登录行为,且完成了至少一次付费转化,那么留存概率较高。
如果用户活跃天数大于 7 天,但最近一周没有登录,且完成了付费转化,留存概率中等。
如果用户活跃天数小于 7 天,但最近一周有登录,且完成了付费转化,留存概率中等。
如果用户活跃天数小于 7 天,且最近一周没有登录,且没有付费转化,留存概率低。看起来逻辑很严谨对吧?但对 AI 来说,这是一个推理分支爆炸的灾难现场。AI 在读取这段内容时,会为每个条件组合建立一个独立的推理分支。四个条件(活跃天数、最近登录、付费转化、留存结果),每个条件 2 个状态,理论上最多 16 种组合。你虽然只写了 4 种,但 AI 会去检查“其他 12 种组合是否被覆盖了”。它会在内部做一次穷举校验——这个过程,就是多跳。
更好的做法是用摩根定律合并冗余条件。比如上面的逻辑,只有一条核心规则:
留存概率高的条件是「活跃天数大于 7 天」且「最近一周有登录」且「完成过付费转化」。
其他情况均属于中或低,且中与低的分界线在于「是否完成过付费转化」。这样一来,AI 只需要做一次条件判断,而不是四路分支。摩根定律的本质就是把“多个条件组合的补集”用“一个否定的并集”表达出来。写文章的时候,多用“否则”“其他情况”来收拢剩余分支,别把每个排列组合都列出来。我自己的经验是:写完一段条件逻辑后,数一数“如果”这个词出现了几次。超过 3 次,就该拆成规则+例外结构了。
陷阱二:信息重复引发 AI“回溯循环”
这个坑更隐蔽。有时候为了强调重点,我习惯在文章不同段落里重复同一个核心观点。比如开头说一次,中间论证时再说一次,结尾总结又一次。对人类读者来说,这叫“强化记忆”。但对 AI 来说,这叫“触发回溯”。AI 在读到第二处重复信息时,会启动一个校验机制:它要判断这两处信息是否一致。如果不一致,它会选择信任哪一处。如果一致,它还要确认是不是同一个来源。这个过程叫做“去重校验”,是 AI 推理中的一个标准化步骤。但问题在于,每次校验都会增加一次推理跳转。
我试过一次。一篇 3000 字的文章里,我把一个核心结论重复了三次。用 AIDSO 爱搜监测豆包的引用情况,发现 AI 在回答相关问题时,优先引用了第一处出现的结论,但后面又去核对第二处和第三处,导致最终输出延迟了大约 1.2 秒——在 AI 回答里,1.2 秒已经算明显卡顿了。
怎么避免?很简单。同一个结论,只在全文出现一次。如果需要在不同位置提及,用“如前所述”“参见第 X 节”这类引用替代重复内容。AI 对这类引用标识的识别率已经很高了,豆包和 Kimi 都能准确跳转到被引用的段落。
陷阱三:否定条件太多导致逻辑取反失败
这个我吃过大亏。写技术文档时,为了追求严谨,我经常写“如果不满足条件 A,且不满足条件 B,则执行方案 C”。看起来没问题,但 AI 在推理时,会对否定条件做一次“逻辑取反”操作——也就是把“不满足 A 且不满足 B”转换成“满足 A 或满足 B 的补集”。转换本身没问题。问题在于,当否定条件嵌套超过两层时,AI 的取反操作会消耗额外的推理资源。我有一次写了三层嵌套:
如果用户不是 VIP,且没有购买过任何付费课程,且最近 30 天没有登录记录,则推荐免费内容。AI 读到这句话,会在内部做三次取反:将“不是 VIP”转换为“普通用户”,将“没有购买过”转换为“新用户或流失用户”,将“没有登录记录”转换为“不活跃用户”。然后它需要把这三个转换后的条件组合起来,再与后续的逻辑做匹配。每一次取反,就是一次额外的推理跳步。
解决方法是:直接用肯定形式表达。上面那句改成“仅对普通新流失用户推荐免费内容”——一个肯定句,把三个条件合并成一个用户画像标签。AI 读到肯定句,直接匹配,不需要做任何取反操作。这其实就是逻辑学里的“否定肯定公式”:把“如果不 A 且不 B”写成“仅当非 A 且非 B”,但更推荐的做法是直接定义一个新的分类标签,把否定条件消掉。我后来写 GEO 内容时,养成了一个习惯:写完一段话,把所有“不”“没有”“非”这类否定词圈出来。如果一段话里出现两个以上否定词,我就重新组织语言,改成肯定形式。读者读起来也更顺,一举两得。
这三个陷阱,都是让 AI 做了“不必要的推理”。你替 AI 省掉一次跳转,AI 就多一分概率采纳你的结论。别让它想太多,它自然会选你。
从 SEO 到 GEO:结构决定 AI 的“最后一跳”
我们聊了五章的逻辑递归、推理终止和跳转陷阱。现在该回答一个更根本的问题了:这些东西,跟传统 SEO 到底是什么关系?
很多人觉得 GEO 是 SEO 的替代品。不是,差远了。Google 的 Danny Sullivan 在 2026 年的 Search Central Live Toronto 上说得直白:AI 搜索的底层逻辑没变,优质内容永远是核心。AI 模型靠通识学习打底,但具体答案依然来自传统搜索结果——它只是换了种呈现方式,把你的排名结果拆成了多跳推理的引用链。
那区别在哪?传统 SEO 关心关键词密度、外链数量、页面权重。你堆一个词堆到 3%,排名可能就上去了。但 GEO 关心的是“你的内容经不经得起 AI 的反复盘问”。AI 不会因为你在段落开头塞了四次“GEO 优化”就选你,它会在内部做查询扩展——把你的文章拆成多个子问题,逐个核对。如果某个子问题在你的文章里找不到明确答案,它就去别家找了。你就在最后一跳被踢出局。
Gartner 在 2025 年的《搜索趋势报告》里给过一个数字:到 2026 年,传统搜索引擎流量将缩减 25%,而生成式 AI 问答入口的占比将超过 52%。52% 是什么概念?超过一半的流量入口,不再是一屏十条蓝色链接,而是一段 AI 生成的回答。你的内容能不能出现在那段回答里,不取决于你的 TDK 写得多漂亮,而取决于你的逻辑链是否完整、结论是否唯一、否定条件是否消干净了。
内容结构一旦清晰到接近数学证明的程度,AI 反而会主动采纳你的结论。它不用来回比对三个地方的同一组数字,不需要把否定条件翻来覆去地取反,更不会在嵌套的“如果……那么……”里绕晕。读完就能直接引用,干脆利落。到了这一步,GEO 的逻辑其实已经变了——让 AI 相信你,比让 AI 找到你更重要。
最后一句话留给实操:下次写完一篇文章,别急着发。把每个结论圈出来,数一数它在全文出现了几次。如果超过一次,删到只剩一次。把每个“不”字圈出来,超过两个就重写。把每个“如果”圈出来,超过两层嵌套就拆成肯定句。做完这三件事,你的内容就已经比市面上 90% 的同行更值得被 AI 引用。别让它想太多。它自然会选你。




评论